For those not aware, Nix is an interesting new application (Nix) and operating System (NixOS) that provides a declarative environment definition and atomic operating system. Declarative means that instead of running apt-get install docker, you write down everything you want and it installs everything and removes everything you don’t want. You can use the same language to manage packages, users, firewall, networking, etc. This is useful because now you can revision control your OS state in Git and have exact replicas across multiple hosts.
My friend, dade, and I have been diving into Nix and NixOS. He got it working on his laptop, I’m trying to get it to be the OS for my four dedicated servers all running Kubernetes. In this post, I’ll walk through the main issues I encountered and how I got a single node running in an existing RKE1 cluster.
I’m not going to go all the way to use Nix to configure everything including my Kubernetes configuration. I know that’s possible, but I already have a Kubernetes cluster deployed using RKE1 that I’m not ready to break yet since it hosts this blog and other services. Maybe in a future iteration I will.
Booting
First, I needed to make the disk as a bootable EFI image:
1
2
3
4
5
6
7
| { config, lib, pkgs, ... }:
{
# Use the systemd-boot EFI boot loader.
boot.loader.systemd-boot.enable = true;
boot.loader.efi.canTouchEfiVariables = true;
}
|
Disk Partitioning
The NixOS minimal live CD does not give a partitioning tool other than fdisk. You’re responsible for figuring out partition types yourself. Luckily NixOS has disko which uses the exact same Nix files to declaratively define partitions and I can steal the config from somebody else who figured it out. Nice.
I had two drives, one SSD, one on a spinning hard drive and followed the disko guide. My configuration looked like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| { config, lib, pkgs, disko, ... }:
{
disko.devices = {
disk = {
ssd = {
# When using disko-install, we will overwrite this value from the commandline
device = "/dev/disk/by-id/5dbd3913-bc15-4e14-9902-de9c1703eacd";
type = "disk";
content = {
type = "gpt";
partitions = {
MBR = {
type = "EF02"; # for grub MBR
size = "1M";
priority = 1; # Needs to be first partition
};
ESP = {
type = "EF00";
size = "500M";
content = {
type = "filesystem";
format = "vfat";
mountpoint = "/boot";
};
};
root = {
size = "100%";
content = {
type = "filesystem";
format = "btrfs";
mountpoint = "/";
};
};
};
};
};
hdd = {
# When using disko-install, we will overwrite this value from the commandline
device = "/dev/disk/by-id/eae13bd2-c505-46b2-9066-5aa1028f10d7";
type = "disk";
content = {
type = "gpt";
partitions = {
root = {
size = "100%";
content = {
type = "filesystem";
format = "btrfs";
mountpoint = "/mnt/hdd";
};
};
};
};
};
};
};
}
|
Writing to the disk was easy (make sure sdb and sda are pointing to the right disks)
1
| nix --extra-experimental-features flakes --extra-experimental-features nix-command run 'github:nix-community/disko#disko-install' -- --flake '/tmp/config/etc/nixos#srv5' --write-efi-boot-entries --disk ssd /dev/sdb --disk hdd /dev/sda
|
Making Vim sane
Nix’s default vimrc configuration is weird for me, but it’s easy to fix this:
1
2
3
4
5
6
7
8
9
10
| environment.systemPackages = with pkgs; [
((vim_configurable.override { }).customize {
name = "vim";
vimrcConfig.customRC = ''
set mouse=""
set backspace=indent,eol,start
syntax on
'';
})
];
|
Moving on to K8s
I’m currently using RKE1 which involves running ./rke up to provision a new node, not NixOS because my K8s is a few years old now. To add a new node it looks like:
1
2
3
4
5
6
7
8
| # cluster.yml
nodes:
+ - address: 1.2.3.4
+ user: adam
+ role:
+ - controlplane
+ - etcd
+ - worker
|
Then run: (--ignore-docker-version is needed because NixOS uses Docker 27.x, but RKE1 only supports up to 26.x)
1
| ./rke_linux-amd64 up --ignore-docker-version
|
And waiting for it to provision.
Resource requests (The dumb issue)
The node joined the cluster, but my next problem is no pods could start because the networking was down:
The kubelet logs (docker logs kubelet) showed:
1
2
3
| kubelet.go:2862] "Container runtime network not ready" networkReady="NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized"
0/4 nodes are available: 1 Insufficient cpu, 3 node is filtered out by the prefilter result. preemption: 0/4 nodes are available: 1 Insufficient cpu, 3 Preemption is not helpful for scheduling..
|

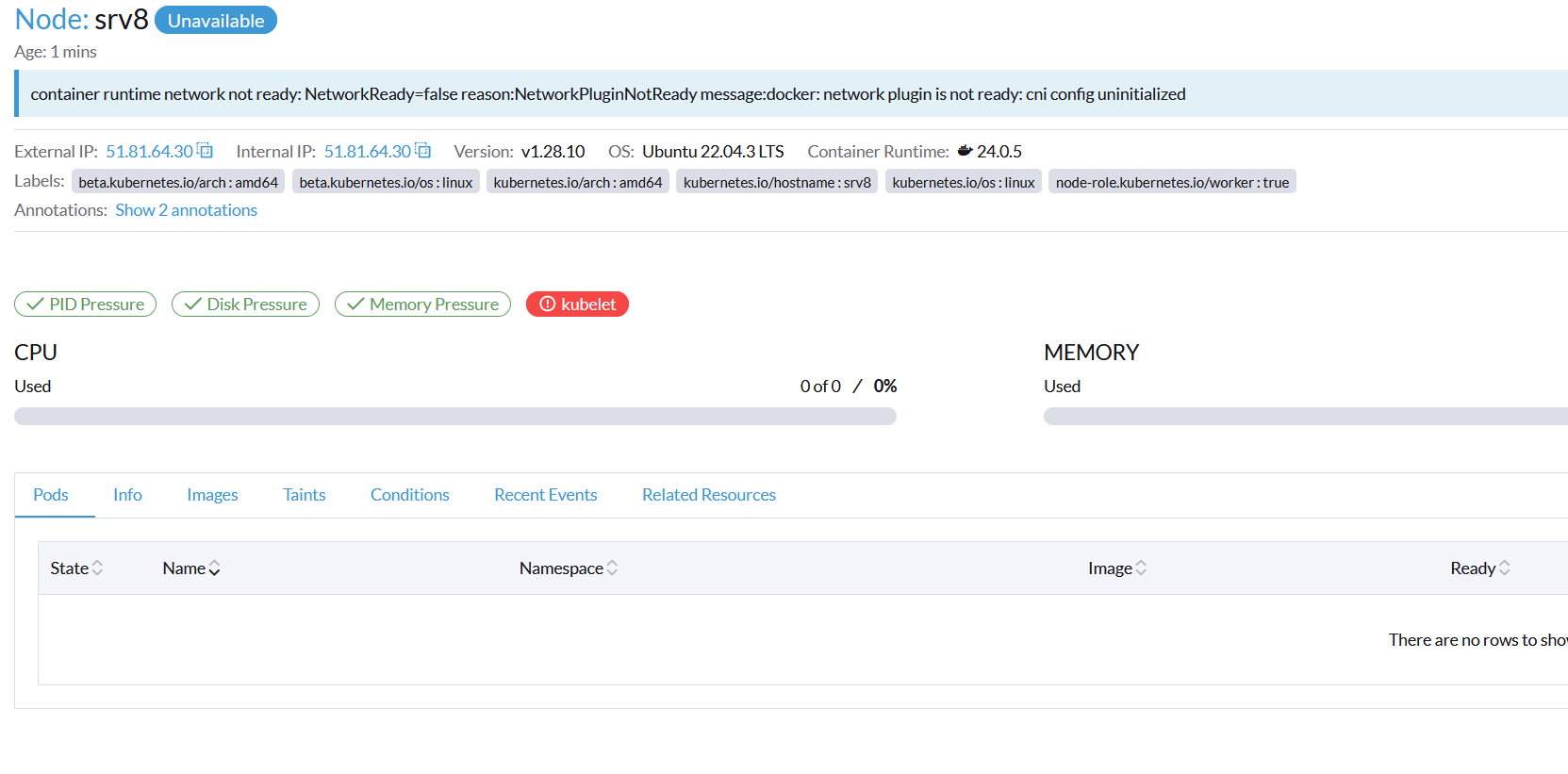
I was stumped. How come there wasn’t enough CPU? Was it because Calico couldn’t spin up, so kubelet was reporting unhealthy because there was no CNI, thus no CPU? A circular dependency?
Nah, let’s get the dumb mistakes out of the way: turns out, I only provisioned one CPU to this test VM because it was just for experimenting, not production use.

And I had reserved 1 core for the host OS:
1
2
3
4
5
| # rke cluster.yaml
services:
kubelet:
extra_args:
kube-reserved: cpu=1000m,memory=512Mi
|
So there was nothing available for the Kubernetes pods itself. Whoops. I gave it more CPUs.
Inter-node traffic
Next problem is diagnosing why the pods weren’t able to communicate with the rest of the cluster. I’m currently using Calico Canal for networking which uses Flannel to create an encapsulated overlay network between the different nodes in the cluster. They weren’t able to communicate and I needed to figure out why, so I installed tcpdump, a packet capturing program. I added the following, then ran nixos-rebuild switch:
1
2
3
| environment.systemPackages = with pkgs; [
pkgs.tcpdump
];
|
On a different node, I pinged a pod running on my test node to identify which ports were needed:
1
2
3
| ping 10.42.4.72
PING 10.42.4.72 (10.42.4.72) 56(84) bytes of data.
|
Gotcha:
1
2
3
4
| tcpdump -f 'host 51.81.64.31 or dst 149.56.22.10'
05:04:55.054420 ens33 Out IP srv8.7946 > srv6.technowizardry.net.7946: UDP, length 96
05:04:55.068243 ens33 In IP srv6.technowizardry.net.7946 > srv8.7946: UDP, length 49
|
Easy enough in Nix to open up the firewall. Ideally, I’d lock this down to just the other nodes in my cluster, but I didn’t know how to do that in NixOS yet.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| { config, lib, pkgs, ... }:
{
networking.firewall.allowedTCPPorts = [
7946 # flannel
8285 # flannel
8472 # flannel
# Kubernetes
2379 # etcd-client
2380 # etcd-cluster
6443 # kube-apiserver
# Prometheus metrics
10250
10254
];
networking.firewall.allowedUDPPorts = [
7946 # flannel
8472 # flannel
];
}
|
Another NixOS rebuild and the pings are flowing between pods.
(it’s always) DNS
All my servers (via a DaemonSet) run PowerDNS as an authoritative DNS server for my various domain names. However, on my new node, it wasn’t able to start up:
1
2
3
| Guardian is launching an instance
Unable to bind UDP socket to '0.0.0.0:53': Address already in use
Fatal error: Unable to bind to UDP socket
|
It binds to port 53/tcp and 53/udp on 0.0.0.0, however systemd-resolved is already running on that port on 127.0.0.53 and 127.0.0.54. Even though it’s listening on loopback, PowerDNS will conflict because it’s trying to run on 0.0.0.0.
1
2
3
4
5
6
7
8
| lsof -iUDP -P -n
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
systemd-r 692 systemd-resolve 11u IPv4 14287 0t0 UDP *:5355
systemd-r 692 systemd-resolve 13u IPv6 14290 0t0 UDP *:5355
systemd-r 692 systemd-resolve 15u IPv4 14292 0t0 UDP *:5353
systemd-r 692 systemd-resolve 16u IPv6 14293 0t0 UDP *:5353
systemd-r 692 systemd-resolve 20u IPv4 14297 0t0 UDP 127.0.0.53:53
systemd-r 692 systemd-resolve 22u IPv4 14299 0t0 UDP 127.0.0.54:53
|
To fix this, I disable the local resolver and point my server to another resolver:
1
2
3
4
5
6
| { config, lib, pkgs, ... }:
{
networking.nameservers = [ "1.1.1.1" ];
services.resolved.enable = false;
}
|
Longhorn
I use Longhorn as my Kubernetes CSI (storage provider) because it supports mirroring across multiple hosts and automatic backups. Under the hood, it uses NFS to mount a volume from the Longhorn storage pod and the host running the application pod. To do this, it requires a few packages to be installed on the host itself (nfs-utils) and the iscsid system daemon.
When I tried to start Longhorn, I got the following error messages because the nfs utils weren’t installed:
1
2
3
4
5
6
| MountVolume.MountDevice failed for volume "pvc-8416dbbf-89cf-45c0-bdc8-8a2b55a4e58a" :
rpc error: code = Internal desc = mount failed: exit status 32 Mounting command:
/usr/local/sbin/nsmounter Mounting arguments:
mount -t nfs -o vers=4.1,noresvport,timeo=600,retrans=5,softerr 10.43.149.52:/pvc-8416dbbf-89cf-45c0-bdc8-8a2b55a4e58a /var/lib/kubelet/plugins/kubernetes.io/csi/driver.longhorn.io/6d6bbeebe575c0ca8e25eb35c0248aca3e81a606bc647be0c2d9901b6b4bd9b3/globalmount Output:
mount: /var/lib/kubelet/plugins/kubernetes.io/csi/driver.longhorn.io/6d6bbeebe575c0ca8e25eb35c0248aca3e81a606bc647be0c2d9901b6b4bd9b3/globalmount:
bad option; for several filesystems (e.g. nfs, cifs) you might need a /sbin/mount.<type> helper program. dmesg(1) may have more information after failed mount system call.
|
As per the Longhorn docs, we need to install a few packages:
1
| environment.systemPackages = [ pkgs.nfs-utils pkgs.openiscsi ];
|
However, NixOS doesn’t place the files in the same place as Longhorn expects (GitHub issue). Longhorn expects to find mount.nfs in the PATH, but in NixOS, it’s actually found in /nix/store/2l9hiinf01ikdjjxd1lafb9mqs5ssfp5-nfs-utils-2.7.1/bin/mount.nfs (the path may differ on your host). When it goes to run nsenter --mount=/host/proc/14084/ns/mnt --net=/host/proc/14084/ns/net mount.nfs in the container to break out of the container into the host namespaces and mount the NFS volume, it looks in the PATH of /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin and doesn’t find it so it fails.
We need to trick Longhorn into looking into the right place by overriding the PATH environment variable. When nsenter runs, it uses the PATH environment to invoke the command on the host OS. I like using Kyverno for this which is a Kubernetes program that can validate and mutate resources based on policies. I used it in the past and already had it installed on my cluster, so this next part worked well.
Inspired by this comment, I created a simple Kyverno policy that mutates every pod in the longhorn-system namespace to include our custom PATH.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: longhorn-add-nixos-path
annotations:
policies.kyverno.io/title: Add Environment Variables from ConfigMap
policies.kyverno.io/subject: Pod
policies.kyverno.io/category: Other
policies.kyverno.io/description: >-
Longhorn invokes executables on the host system, and needs
to be aware of the host systems PATH. This modifies all
deployments such that the PATH is explicitly set to support
NixOS based systems.
spec:
rules:
- name: add-env-vars
match:
resources:
kinds:
- Pod
namespaces:
- longhorn-system
mutate:
patchStrategicMerge:
spec:
initContainers:
- (name): "*"
env:
- name: PATH
value: /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/run/wrappers/bin:/nix/var/nix/profiles/default/bin:/run/current-system/sw/bin
containers:
- (name): "*"
env:
- name: PATH
value: /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/run/wrappers/bin:/nix/var/nix/profiles/default/bin:/run/current-system/sw/bin
|
After that, I redeployed the Longhorn pods and the containers were able to start up without crashing.
iSCSI
However, trying to mount a volume on the host would fail:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| failed to execute: /usr/bin/nsenter [nsenter --mount=/host/proc/14084/ns/mnt --net=/host/proc/14084/ns/net iscsiadm -m discovery -t sendtargets -p 10.42.0.20], output , stderr
iscsiadm: can't open iscsid.startup configuration file etc/iscsi/iscsid.conf\n
iscsiadm: iscsid is not running. Could not start it up automatically using the startup command in the iscsid.conf iscsid.startup setting. Please check that the file exists or that your init scripts have started iscsid.
iscsiadm: can not connect to iSCSI daemon (111)!
iscsiadm: can't open iscsid.startup configuration file etc/iscsi/iscsid.conf
iscsiadm: iscsid is not running. Could not start it up automatically using the startup command in the iscsid.conf iscsid.startup setting. Please check that the file exists or that your init scripts have started iscsid.
iscsiadm: can not connect to iSCSI daemon (111)!
iscsiadm: Cannot perform discovery. Initiatorname required.
iscsiadm: Could not perform SendTargets discovery: could not connect to iscsid
exit status 20
Nodes cleaned up for iqn.2019-10.io.longhorn:unifi-restore" func="iscsidev.(*Device).StartInitator" file="iscsi.go:168
msg="Failed to startup frontend" func="controller.(*Controller).startFrontend" file="control.go:489" error="failed to execute:
/usr/bin/nsenter [nsenter --mount=/host/proc/14084/ns/mnt --net=/host/proc/14084/ns/net iscsiadm -m node -T iqn.2019-10.io.longhorn:unifi-restore -o update -n node.session.err_timeo.abort_timeout -v 15], output , stderr
iscsiadm: No records found
exit status 21"
...
|
It can’t find the iscsid service provided by the iscsid.socket and iscsid.service systemd units. Just installing the package doesn’t enable the service. For that we need to add:
1
2
3
4
5
6
7
8
9
10
11
12
| { config, lib, pkgs, ... }:
{
environment.systemPackages = with pkgs; [
pkgs.nfs-utils
pkgs.openiscsi
];
+ services.openiscsi = {
+ enable = true;
+ name = "iqn.2005-10.nixos:${config.networking.hostName}";
+ };
}
|
Then redeploy the application pod.
I forgot the Firewall
At this point everything is deploying, but I can’t seem to access anything running on this host. Normally Docker and Kubernetes hijack the IPTables rules, but on NixOS they don’t. Easy fix:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| networking.firewall.allowedTCPPorts = [
53
# nginx
80
443
# mail
25
110
143
465
587
993
995
7946 # flannel
8285 # flannel
8472 # flannel
# Rancher UI
8443 # I don't know if this is actually used
32121
# TODO: Lock these down to intra-node only
2379 # etcd-client
2380 # etcd-cluster
6443 # kube-apiserver
10250
10254
9100 # prom-node-export
];
networking.firewall.allowedUDPPorts = [
53
7946 # flannel
8472 # flannel
];
|
Missing kubelet logs
Next, I had an issue where kubelet logs would not show any logs from any pods:
1
2
3
| $ kubectl --context=local -n cattle-system logs helm-operation-hpq86
Defaulted container "helm" out of: helm, proxy, init-kubeconfig-volume (init)
failed to try resolving symlinks in path "/var/log/pods/cattle-system_helm-operation-hpq86_f63d99d0-ad39-478f-be8f-bdc1f4657d1d/helm/0.log": lstat /var/log/pods/cattle-system_helm-operation-hpq86_f63d99d0-ad39-478f-be8f-bdc1f4657d1d/helm/0.log: no such file or directory
|
Looking at the host, no files were present in /var/logs/pods and nothing was in /var/lib/docker/containers/{container}/*-json.log. The default logDriver in Nix for Docker is journald. I tried switching to local which didn’t work, but this StackOverflow post suggests it needs to be set to json-file.
Easy fix. I changed updated the logDriver and nixos-rebuild switch to restart the Docker daemon fixed my logs:
1
2
3
4
| virtualisation.docker = {
enable = true;
logDriver = "json-file";
};
|
Conclusion
Thus far, I feel that Nix is powerful and I like having declarative config that can manage everything about the OS. I can define a series of configuration files and define per host flakes for my servers and computers and pick and choose which machines get what config.
But I don’t find the language itself very intuitive. I tried to create my own derivative, but ran into issues. Over time, I hope it gets better though and I’ll keep playing with it.
