Since Intuit announced that Mint was going away, I’ve spent several months investigating how to import my Mint data into Firefly-iii, an open source, self-hosted budgeting software. It seemed like a perfect fit. I would fully own the data and get to build whatever tooling I want on top.
However, before we can get there, we need to have cleaned and accurate data from Mint. As it turns out, Mint’s data actually had some errors in it that required me to go back years and fix them. In this post, I walk through the programmatic approach I took to identifying mistakes and fixing them.
Downloading
I previously talked about downloading data from Mint in Monarch Money and ad networks. Also download the daily balances. I also used the Monarch Money Data Exporter to download daily balance info.
Understanding the Firefly model
Importing into Firefly is tricky because it calculates the current balance of an account as the sum of all credits and debits. This is good in theory, but it requires you to have perfectly accurate transaction data going back to the account opening date. Most other tools, like Mint, Monarch, Personal Capital, all seem to track as a series of transactions and the balance is just collected from the bank and is not a function of the transactions. That’s easier to implement because it doesn’t require the full history and is robust against errors
Additionally, Firefly-iii supports explicitly modelling transfers between two accounts. In effect, the two separate credit and debit transactions are linked together. This is problematic (and you’ll see why) because no bank actually tracks the opposite transaction, nor does Mint.
Importing using the Firefly importer
Firefly has a default importer. It’s a separate Docker container that enables you to import from a csv file.
The importer has performance issues, doesn’t scale when loading large amounts of history. It would fail to load and crash when trying to do an entire year of transaction data.
Data from Mint isn’t clean and has a few duplicates here and there.
Identifying transfers is tough. It has no concept of being able to identify a transfer itself given two halves. The only way is to set remap the description as an opposing account, but descriptions aren’t consistent.
For example, these are all transaction descriptions from Mint with different formats. I know they’re on the CAPITAL ONE side and I know which account they pull from, but I had to manually remap every single month:
- CAPITAL ONE AUTOPAY PYMT AuthDate 09-Oct
- CAPITAL ONE AUTOPAY PYMT AuthDate 09-Sep
- CAPITAL ONE AUTOPAY payment AuthDate 05-N ov
- CAPITAL ONE CRCARDPMT
An ambiguous example:
- Internet transfer from Interest Checking account
- Internet transfer from Online Savings account
Which account was it transferred from? This simply wasn’t going to work, so I gave up using the tool.
Importing using Pandas
Pandas is a popular Python package designed for data processing and manipulation and great for working with CSV files like this. It should be more scalable and able to handle these ambiguous cases.
Loading
| |
Comparing expected vs actual balances
First, we need to check to see if Mint even has the right transactions (foreshadowing). Let’s compute the total balance based on all transactions:
| |
Next, load the balances as measured by Mint. The folder /data/mint-balances contains .csv files with the schema: Account Name,Date,Amount. I downloaded this using the Monarch Money Data Exporter before Mint shut down entirely.
| |
Join to find error
| |
Stock brokerage accounts I focused just on the cash based accounts (excluded anything with any type of security pricing such as brokerages, IRAs, etc.) and then compared the balances with the actual balances to find the balance error. In theory, if Mint were have collected data perfectly accurately, all error balances would be $0. However, it was not.
| Account Name | balance | actual_balance | balance_error |
|---|---|---|---|
| A | $4,000.0 | $2,000.0 | $2,000.0 |
| B | $500.00 | $500.0 | $0.00 |
| C | -$1,000.0 | $600.00 | -$400.00 |
Unfortunately, errors are hard to track down because the error can come from anywhere.
Duplicates
One source is duplicated transactions. Duplicated transactions aren’t guaranteed to be bad, but could be. For example, if you pay with your phone at MTA, you’ll end up with a transaction for the same price for each ride.
| |
How you actually verify whether the duplicates are correct will vary. If you have access to the original statements (not likely if you’re past 7 years), then you’re going to have to use intuition. For example, I purchased something at a 0% financed rate. The payment is the same every month, so if there’s a duplicate, it’s wrong. My Capital One card allowed me to fetch any statements from the open date, my Citi and Amex cards required me to request transactions, and other cards I was out of luck.
One account, like the “Account A/(Fidelity Cash Management)”, had an error of -$43.47. This was easy because I found a duplicate transaction:
| Date | Description | Type | Amount |
|---|---|---|---|
| 9/25/2018 | Cash Withdrawal | debit | 43.47 |
| 9/25/2018 | Cash Withdrawal | debit | 43.47 |
Removing one from my .csv file brought the error for that account from -$43.47 to $0.00.
Comparing balance over time to identify errors
Once I identified which accounts showed errors, I compared the estimated balance vs the actual balance. The estimated balance is the cumulative sum of the credits and debits each day, and the actual balance is the daily balance as measured by Mint. This balance is collected when it scrapes the account so it should be accurate. Before this we compared just the ending balance, but this approach breaks it down as a time series which should help us narrow down to the exact date when an error is introduced.
| |
This next diagram shows the difference in the daily balance calculation.
This chart is very noisy and not helpful yet. But wait, let’s zoom in! There seems to be a noticeable pattern:
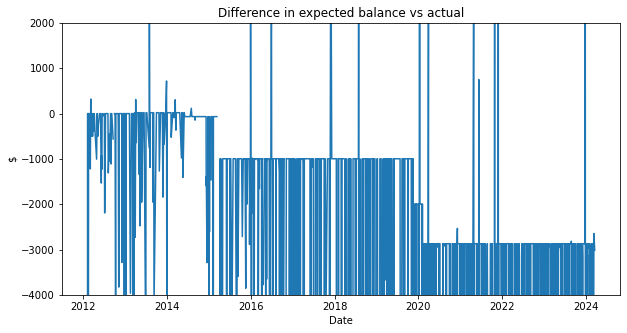
As it turns out, the Mint collected account balance isn’t always right because 1) Mint doesn’t update every day and 2) pending transactions aren’t always included in the balance. To fix this, we can calculate a rolling average and drop out the error:
| |
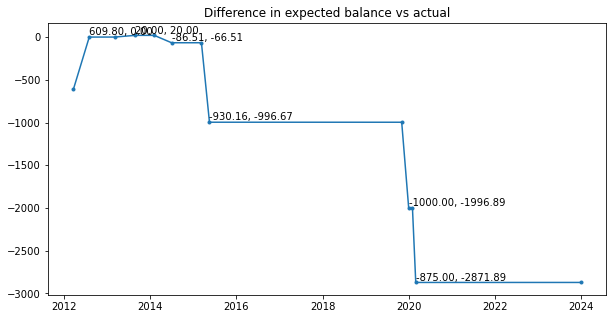
Now I know to check between Mar 6th and April 26, 2013 for either an extra $20 credit or a missing $20 transaction. As it turns out there were two $20 credits. The same thing happened with the $1k difference in the end of 2019. This seems to be the common mistake.
This method worked pretty well for cash based accounts, but trying to apply it to a credit card broke down because every transaction goes through a pending phase for a few days, far more than the cash accounts did. Even after tweaking the denoising algorithm, it still wasn’t able to find the error points even though I could very clearly see it with my eyes.
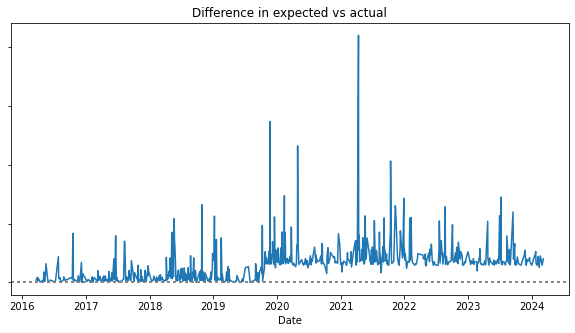
I realized the most common failure point seems to be duplicated transactions, so can I specifically test for them? I came up with the following algorithm, first I identified all of the duplicated transactions, then it simulates removing one of the duplicates, if it reduces the error, it saves the transactions for further testing.
| |
Once it has a list of possibly incorrect duplicates ordered by how much it reduces the error, and iteratively simulates removing multiple transactions until it no-longer improves. These transactions are the ones that have a high likelihood of being invalid. To confirm, use your memory or check your statements.
| |
Then finally render the simulations:
| |
Running this gets us the following. The second graph shows the error duplicates are removed (Lower is better). The first graph shows the default line along with the simulated removals. It’s a little hard to see, but at the very end, the error gets corrected back to 0 by removing the duplicates.
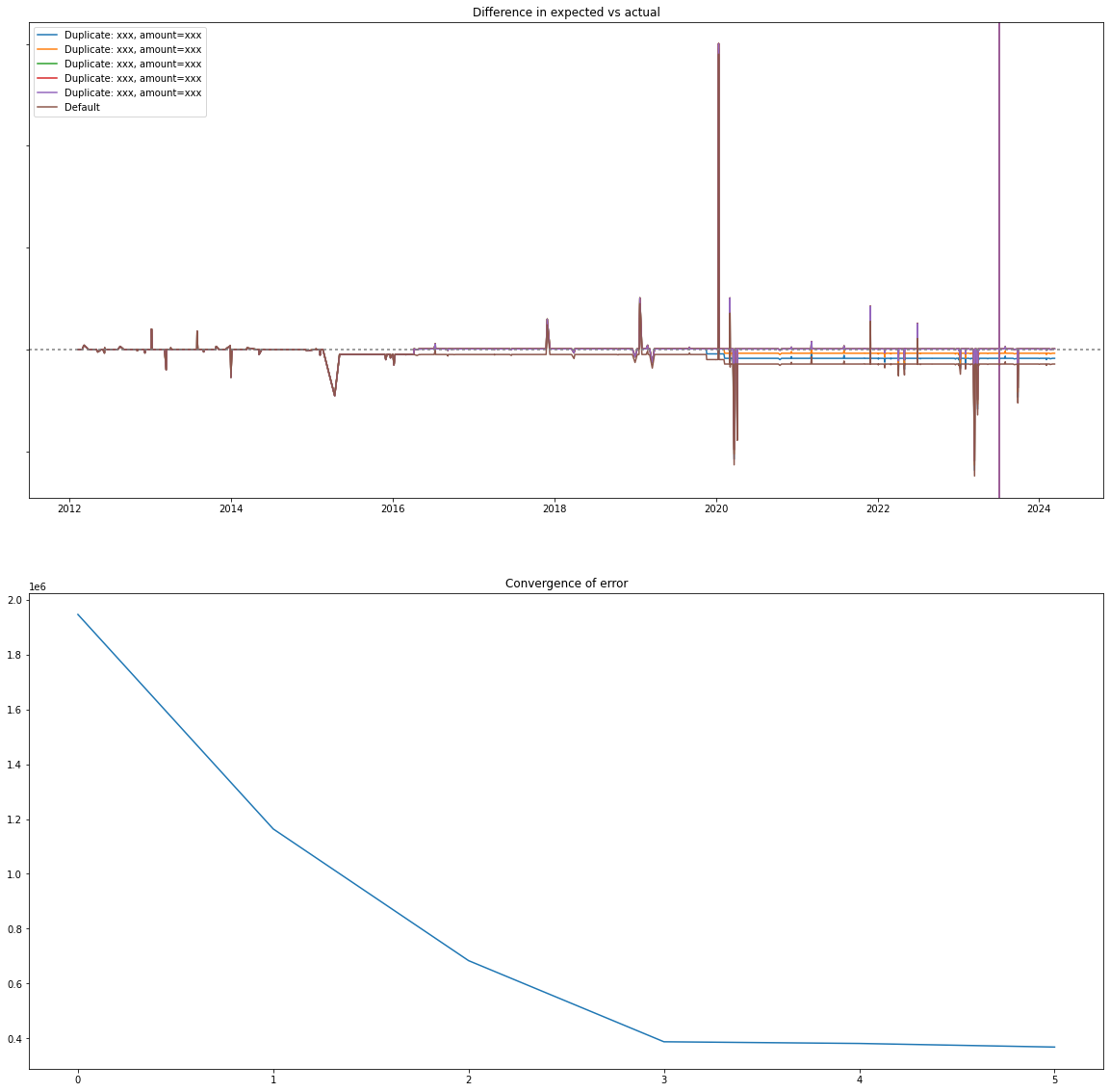
Note, this may have false positives or false negatives. It’s calculating based on what looks right. However, it should give you some places to look. In my case, I looked at these transactions and deleted them from the CSV because they were wrong.
Dummy Transactions
The last strategy I employ is to just add dummy transactions to correct any errors. Find the earliest statement you can get for an account and see what the starting balance is. Then compare that with your estimated balance. Whatever the difference is can be added as an initial balance transaction.
| |
To calculate the initial balance, subtract the RunningBalance from the expected balance and create a manual transaction:
| |
All Together
If you want to see the (messy) code all together, take a look at the GitHub repo ajacques/own-your-finances.
Next Steps & Conclusion
Now, we should have a Pandas DataFrame containing cleaned and accurate transaction data. We identified multiple strategies to identify bad transaction data In Part 2, I’ll walk through how to identify the transfer pairs and actually import it into Firefly. At some point, I’ll figure out how to link this up to pull transaction data from accounts.
If you’re in the United States, then you basically have no good options for accessing your data yourself without paying other companies (e.g. Plaid, Akoya) to screen scrape or integrate with restricted APIs. I’ll dive into this more in a later post, but this is why I’m very interested in the CFPB’s proposed rules on CFP1033. For awhile they were accepting public comments here, but that’s closed now.
Errata
- 2024-04-25 - Fix bug in
render_bal_chartbecause I had an extra parameter that shouldn’t apply to other users. Added better validation.
