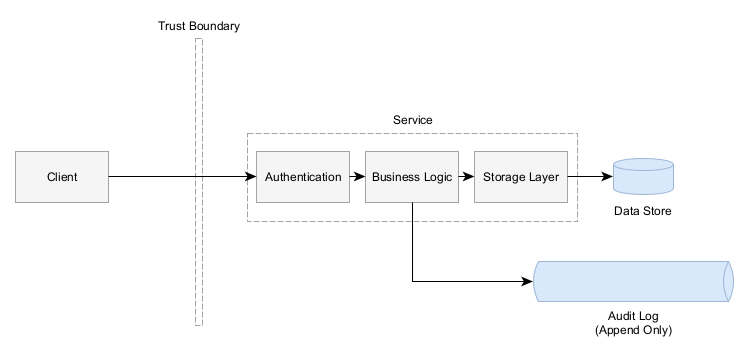
If you’ve got a service that provides clients with the ability to make changes to those entities, then you probably want an audit log that tracks who makes what changes.
I decided to write this post because I frequently saw teams at Amazon not thinking through these considerations. Some of the guidance does focus on AWS IAM, but a lot of it is practical for any type of audit log.
Important aspects to an audit log:
- Who made the change?
- When did they make the change?
- Where did they make the change?
- What did they do?
Not all audit logs are the same. I predominately worked in services that owned some kind of data, then needed to track who and what changes were made to its data in a SOA (Service Oriented Architecture) environment. An audit log that tracks user sign-ins or other types of operations may not have any changes to an entity, but they still have a Who, When, and Where.
Terminology
- Principal - An authenticated entity that can make calls to your service. Can be a person, computer, or a service
- Service Principal - A Principal that represents a service. Since a service may be made up of more than one host/process/AWS Account, this uniquely represents the service
- User Principal - A Principal representing a human.
Characteristics of the Log Itself
Append Only
Audit Logs are built for security purposes to know who made a change. If a malicious actor can rewrite the audit log to hide their tracks. An audit log must be append only. It should not be possible for any entries to be deleted or modified. The service should only have the ability to write new entries.
Consider the Domain instead of Storage
I wrote an earlier post about the difference between domain models and storage models that is relevant. The domain model are the core classes that you implement business logic upon, whereas the storage model is what that domain model when forced into the limitations that a given data store requires.
Your audit log should be composed of changes to the domain, not based on the storage model.
Versioned
Take care when designing the schema for your audit log, since it has a longer lifetime than your storage schema. With a database, you can run migrations to upgrade the schema, but for security audit logs may be append only and not allow any writes.
Who made the change?
Who called you is really what person or system made the change. This identity should come directly out of your authentication system It may seem easy at first, but make sure you don’t make any bad assumptions.
Find a meaningful service identity
When you’re processing a request, you need to think about your authentication system to figure out what types of identities you have. Does your authentication handler give you a user id or is it generic like an AWS IAM ARN?
If you use AWS IAM for all calls to your service both human and services with something like Cognito (which I don’t recommend using,) then you’ll get several different pieces of information such as an ARN (eg. arn:aws:iam::1234567890123:root) and session tags. Use this information to convert to something meaningful like a user id or map the account id to a known service name.
arn:aws:iam::1234567890123:assume-role/UserAccessRole_ + STS Session Tags -> userid:2345 (user: foobar123)
Don’t assume that all callers are the same type (e.g. always human)
I’ve frequently seen services just store a username as a string in the event log:
| |
What happens if your service also allows non-humans, such as service callers? If you used to store a username like “foobar123” in username, now trying to store a service identity like “InventoryForecastingService/Prod” in the same field is not useful because you don’t know if it’s a human or service.
Instead, distinguish between identities from different identity providers by including a type:
| |
Consider systems acting on behalf of another identity
Sometimes services will need to call another service, but will be acting on behalf of another identity, such as a user. This might happen in a transitive service call, when a user calls a service that then needs to call another service:
![]()
When Service B receives the request, it’s important that it logs both identities since Service A calling it is different than the user calling directly.
There’s two different ways of representing this:
- The primary caller is ServiceA and an optional OnBehalfOf attribute denotes the transitive user
- The primary caller is UserA and an optional Via attribute denotes the service that made the call
I’ve built systems with both cases, but I prefer the second solution because generally authorization systems primarily evaluate the user permissions and service permissions are coarse grained and the relevant principal is the user.
Make sure to log both principals to the log:
| |
Example from AWS CloudTrail
For a practical example, we can take a look at how AWS CloudTrail exposes their identities to AWS customers (docs).
Note how depending on the type, there are different relevant attributes:
| |
When an internal AWS service calls your service, it doesn’t provide any of the internal details and instead exposes a service principal. While internally they’re using IAM, this is an example of how the low-level IAM identity may get mapped into a more meaningful identity when stored in a log:
| |
Consider privacy laws like GDPR and use non-changing identifiers
Privacy laws like GDPR will come into play when you’re storing a user’s actions in a log. Often times usernames are the user’s email address which has two problems: it can change and they are considered personal information.
Instead of storing a username or email address in the log, use a unique, non-changing user id that refers to the actual user in another identity service. This reduces the number of services that store sensitive personal information.
Where did they make the change?
Now we know who supposedly made the change, but what happens if a malicious actor secured valid credentials to a user? The next part is including relevant information to aid any investigation.
Some information to include:
- Timestamp
- IP Address
- User Agent
- Session Id
What change did they make?
The next problem to solve is to figure out how to represent what mutations they made on the models.
Audit logs should be thought in terms of the domain, not the storage model. The domain model are the core classes that you implement business logic upon, whereas the storage model is what that domain model when forced into the limitations that a given data store requires. I wrote an earlier post about the difference between domain models and storage models that is relevant.
Snapshot
A snapshot based log stores a snapshot of the entity at each version.
| |
Snapshots make it easy to revert and back to prior revisions, but to actually figure out what changes in between v2 and v3, you need to grab both versions then diff each field. This can get quite complex if you have complex objects with nested fields or arrays.
Diff
A diff based log stores only the values that changed from the previous version.
| |
Reading through from v1 to v3, we see that the first entry includes all fields because it’s newly created. The second entry only contains the email change.
But how do we represent the third change? Primitive types are easy to represent, but how do you represent an array? If you represent it as ["CAN_READ", "CAN_WRITE", "CAN_FOO"], the new entire value, then it’s effectively a snapshot at the field level and you need to still do a field level diff to identify the change.
Another way is to break down the changes to arrays into additions and removals:
| |
Now the audit log clearly states what *changed* in v3 of the log. Other complex types can be broken down similarly.
How does this relate to Event Sourcing and CQRS?
In conventional data store patterns, the service will read and write to the same entity in the database with no separation. The database does not inherently maintain a log of changes to a given entity and an audit log must be created independently of the main entities.
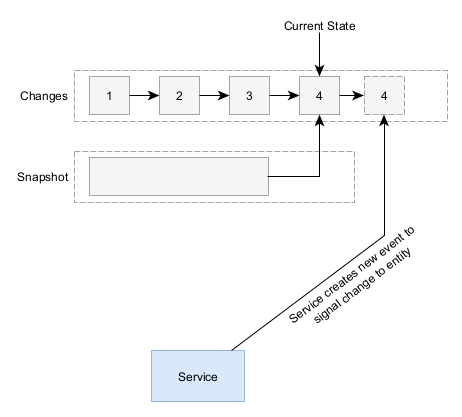
Event sourcing is an architectural pattern in which the data store actually maintains the events and changes to a given entity. The current state of an entity is discovered by replaying all of the events from the start. For performance reasons, event sourcing systems often times create periodic snapshots so the entire store doesn’t have to be scanned.
This has the advantage that the change log inherently represents most of the information in an audit log (the change to the entity) and just needs to be supplemented with identity information to become useable.
While this inherent audit log behavior is quite valuable, there are a few disadvantages. In a sample architecture built upon AWS DynamoDB:
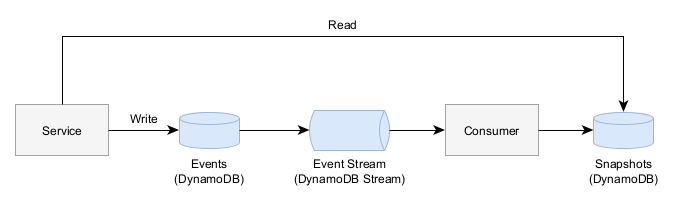
Worse Consistency - While data stores like DynamoDB do have eventual consistency where a write may not be instantly seen by a read afterwards, this can become even more prevalent in event sourcing data stores (especially if you build them on-top of other data stores.)
Each event must be strictly serializable such that event B comes after event A. In the above sample architecture, this means that when you create a new event you must get the latest snapshot and apply all pending events before you can create a new event.
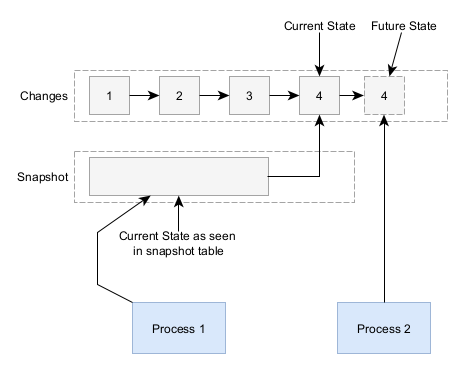
Lack of Type Safety through Strong Domain Models - As I mentioned in my blog post about domain model safety, my preferred strategy is to develop strictly validated domain model classes that implement business logic. Only when the entity is saved is it converted to a loose storage model and saved to the data store. This becomes very challenging in the above sample architecture. Any validations must be performed when the event is created and before it’s saved since any invalid customer input should result in a 400 error to the client.
However, the service merely creates events that “request” an entity to be changed. The consumer is the component that actually makes the change and saves it. If the consumer rejects a change then it could block processing of other events and cause a system outage.
Instead, the event should only be created if it results in a valid entity on the output. Unfortunately this can be challenging to implement in code since validation logic needs to be implemented in each command that creates an event. There’s no one single, central place that enforces validations.
Architectural Complexity - In the sample architecture, there are more moving parts involved. All of this adds more things you have to monitor, more code written, and more things to deploy. Developer time isn’t free and systems will break in weird ways at 3am on a weekend.
Conclusion - Both strategies, event sourcing as the audit log and separate audit logs, have advantages and disadvantages. I’ve worked in multiple systems and have had a chance to see both in practice. The goal of this post was to introduce some of the differences and help ask questions so you can build the best solution for your project.
How do you identify changes?
Now that we have some characteristics of a good audit log, how do we actually generate audit events in the source code? This is going to depend heavily on your language and frameworks. In my work, I always used in-house built solutions. Automated solutions didn’t really do what I needed. However, some of the below libraries may be valuable:
- Java - Javers
- Ruby on Rails - paper_trail gem - This one seems to use the snapshot style to store revisions so you have to compute diffs yourself
Conclusion
In this post, I walked through various aspects of useful audit log for services that control access to a data set and allow users to make changes. This should provide a framework of questions and concerns for you to build your own audit log.
