How to make your system robust against your worst nightmare–your future self
In this post, I talk about some strategies that I’ve learned to simplify class structures in Java services that load and persist data into data stores like DynamoDB or RDS at the same time making the codebase safer.
As always, my opinions are my own.
At Amazon, I ended up joining two teams that were suffering under the technical debt. Each time, I was asked to spend some time understanding why the products were unstable and users were encountering frequent bugs. In one system, responsible for managing critical metadata about products in the catalog, was experiencing problems where users were reporting that they’d randomly lose data.
A service that was losing client data is a terrible service and caused users to lose trust in this system. Note that some details of this story have been modified for confidentiality reasons. Let’s dive in.
Cognitive complexity in software engineering is the effort that one has to spend to understand and modify a code base or system. The abstractions we use and APIs we expose are a big part in increasing or decreasing this mental burden.
Background
In this system inspired by real life, there was a web UI that called into a REST service which then persisted data into a graph database, AWS Neptune.
The primary data in this system was a Project which included a number of Values both containing a variety of different fields. The data was stored in a graph database in AWS Neptune and the service used Eclipse rdf4j as a high-level ORM that mapped Java classes into the SPARQL queries (SPARQL is the language used to query and mutate Neptune databases.)
Problems in every interface layer
There were many problems with this system. First, the service used rdf4j to save the entire Project entity to the database. The query language, SPARQL, only gave guarantees about transactions at a per triple level (effectively a entity column or field level), but for updates spanning multiple columns/fields, any concurrency would just cause broken consistency. Neptune was the wrong choice for this problem.
Second, the REST service didn’t expose fine-grained edit APIs to apply business logic or mutate specific fields on the objects. Instead it exposed a single giant UpdateProject API in which the client-side JS code would make changes to the record locally, then persist it to the service. Combined with the above, the likelihood of corruption was high.
Third, (the point of this post) the Project entity class was written exactly like rdf4j needed to persist.
The class looked something like this:
| |
There were a few key problems:
The object tried to be immutable, but the object itself didn’t handle cloning. Instead the calling code had to construct a new instance copying fields and changing as it went. This was inconsistently applied and every place that modified the object ended up being lots of boilerplate to clone and mutate.
This object is the class structure that rdf4j needs to be able to load the objects. It exposed getters and setters for every single field directly as rdf4j used Java reflection to create an instance, then called set*() to populate the object as it loaded it into memory. Other code in the same system had full access to modify every single field in this instance and even get this object into invalid states.
Storage Layer Interface
The storage layer (sometimes called a DAO-Data Access Object) is the component that is supposed to abstract out interactions with the data store and provider APIs to load and save. The interface looked a little like this:
| |
This interface also contributed to the problems. There’s only a single save method that saves the entire record to the data store and it used some kind of optimistic locking (using a version counter to identify concurrent writes) to prevent two users from modifying the same record.
However, if your object has a lot of fields and many people concurrently modify it, the risk of a version conflict exception grows higher even if those independent operations could be applied atomically. Not every model easily lends to lots of independent concurrent updates to the same record. In this post, I’ll give two examples. This example could be broken down into separate entities, but breaking down operations past that was challenging because we would have needed version tracking per field.
Influence on the rest of the system
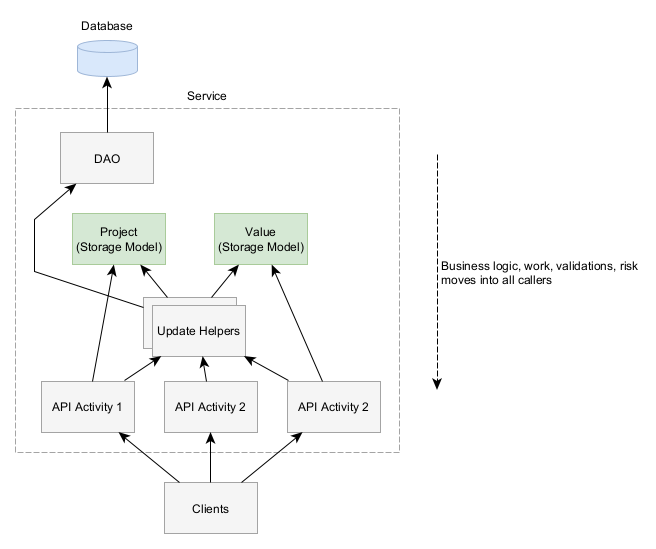
Let’s look at how the system evolved in a system shaped like this.
Decentralized business logic
First, because the storage models (in green) encapsulate no logic, the business logic gets pushed outside into the callers. Business logic might include making some change to one or more properties on these entities and ensuring they continue to maintain correctness.
The logic was decentralized and could be bypassed by interacting with the classes directly. The team created utility classes to help perform changes to the entities, but this led to decentralized logic You have to know where to look to find them and how to use them. If you’re trying to interact with a domain model, do you look on that model, or do you look around in other Java packages to find a relevant util or helper class? Different developers did different things because nothing forced them to be consistent.
Proliferation of storage limitations
Data stores bring with them many limitations on what you can store in them. For example, Neptune required you to store values as a literal (a string, numeric or boolean) leading the system to use strings to represent values with no validations. A developer could have easily added whatever they wanted by accident and that may or may not have been caught by the validate method (assuming it was called or a validation was added.)
| |
DynamoDB has its own limitations, too and the common DynamoDBMapper tries to map types, but something as simple as a Set
Developers couldn’t create custom classes or use the best data type for the situation.
Abstractions in Layered Systems
As you went higher in the stack, abstractions should become more abstract and less aware of the details, but in this case the models were not able to hide the complexity and everything had to be aware of how the database stored objects. Each layer added only minimum abstraction value and mostly punted to problem upwards.
What is the domain?
Every system has a domain. The domain, in this case, represents the business problem that you’re trying to solve without considering constraints like database structures. The domain models should be considered the best way to reason about the business concepts working in memory.
The above class structure doesn’t model the domain, it represents the limitations of the databases and those limitations imposed on the entire rest of the system.
Separating the storage concern from the domain
The first thing we need to do as build a good domain model class that represents exactly how we want to think about the business logic.
Let’s create the class.
First, there’s no default Setter methods. We only expose read-only access, but explicitly control which attributes have setters.
| |
Instead of before where we had a no args constructor that allowed the ORM to create empty objects to later populate, developers MUST provide the minimum set of values required. After the id or versions are set, you can’t modify them.
| |
Let’s use appropriate data types for timestamps instead of longs so they’re validated automatically by Java.
| |
Now we’re getting to the important part of the domain model. Don’t worry about names or anything, but note how instead of storing the states as a Set
We also don’t expose the raw state map instead only exposing read-only access. All writes have to go through methods that ensure it’s a safe transition:
| |
Now instead of higher layered methods having to worry about how to apply a change, they only call the method and the model figures out how. This simplifies those higher-layers making them easier to read and understand because they’re phrased in terms of the domain.
The Storage Layer
We locked down access to the domain model, but the storage layer needs to be restricted. It can’t return or take in a storage model otherwise developers could just save whatever they want.
Instead, the class should only take in the domain model, then translate it from the domain model into a storage model, then submit the API request.
| |
Now, it’s not possible to bypass any validations on the model and in theory all objects should be perfectly valid in the data store.
Another Example - Devices
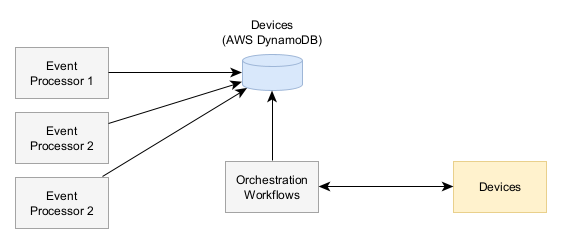
This system responsible for managing the status of tens of thousands of devices, was having problems where devices would get into unexpected states and break requiring manual intervention by a user or by the service team developers.
The operational burden was becoming unmanageable and the dev team was getting burned out.
Background
In this example system, the primary resource can be called a Device and each device had numerous status fields tracking the desired state, actual state, and other various health statuses.
The architecture involved a lot of concurrency on each device record in the database as at any given point multiple processes could be requesting updates to a single device or processing the updates getting pushed to the devices. Due to the low latency requirements, we couldn’t just serialize all updates to each update device record.
Class Structure
Since this was a set of Java applications that were interacting with DynamoDB, we were using DynamoDBMapper as a higher-level interface for reading and writing records to the database. In this world, you annotate classes with annotations that tell DynamoDB which attributes to save to which columns and it constructs the API calls for you.
In our example, the device class looked like:
| |
Similar to the previous example, everything is fully open. One key difference with this example was that there were multiple writers that were all operating on different parts of the record to maintain that low-latency requirement.
Events were coming from the devices about the state of the world that needed to be persisted to the store. Because it’s the state of the world, it should be considered to be absolute truth. Thus we wanted to always update this field without considering version conflicts.
This was done by using DynamoDBMapper’s SaveBehavior.UPDATE_SKIP_NULL_ATTRIBUTES which stated it would only save fields that are non-null. The system only populated the id and field to change and left everything else as null.
Effectively the code looked like this:
| |
The goal was that only the changed fields would get saved and nothing else would get saved, however this skips null attribute values. What happens if you want to change desiredContent to be null? It can’t be done. This actually actually made it to production and caused a bug.
Solution
We applied similar refactoring techniques here: created a domain-focused model and a refined storage layer that only accepted domain constructs to load/save.
However, what was different is that this service had low-latency requirements and couldn’t use record-level versioning with retries for changes that were completely orthogonal. Instead it needed to be able to apply changes to the records atomically with no record-level versioning using field-level concurrency using DynamoDB’s Conditional Expressions.
We also banned the usage of UPDATE_SKIP_NULL_ATTRIBUTES due to the ease in causing a bug.
This required more focus on the storage layer API to expose just the right level of abstractions.
| |
Now for these patch operations, we exposed a updatedActualContent API on the storage layer. This contrasts with the strategy in the first example which was only a single save API. However, this is a safe change because the device was reporting it’s state. There’s no world in which the actual state coming from the device should be rejected due to a conflicting write.
Since we couldn’t use the SKIP_NULL flag, we instead created specific patch objects:
| |
And the storage model used that instead:
| |
Thus allowing us to change fields to be null and apply these changed atomically and concurrently in DynamoDB.
Conclusion
After applying this technique across these two teams, we were able to eliminate data corruption issues caused by bugs in improperly applied business logic. This dramatically reduced the cognitive complexity of the system and helped developers move faster because they knew they could rely on the safety of the model.
Don’t follow best practices blindly. When I asked engineers why they made some choices (like the immutable objects) and they said that they thought it was a best practice and were trying it out. Nobody questioned whether it made sense in the case. If somebody claims some thing is a best practice you need to understand why, does it make sense, does it even apply in your situation? Not every best practice is really even that good.
A lot of developers have the mentality that because the code is internal, developers won’t make mistakes and accidentally forget a validation or apply an improper change to the object. However, one thing I’ve realized is that without being malicious developers frequently make mistakes because modern code bases become gigantic and it’s hard to keep track of every expectation.
When designing your classes, you should instead think about how to model your business logic intelligently and safely, then separately how to save within the limitations of your data store. This will reduce the cognitive overhead.
