In previous posts, I leveraged the MACvlan CNI to provide the networking to forward packets between containers and the rest of my network, however I ran into several issues rooted from the fact that MACvlan traffic bypasses several parts of the host’s IP stack including conntrack and IPTables. This conflicted with how Kubernetes expects to handle routing and meant we had to bypass and modify IPTables chains to get it to work.
While I got it to work, there was simply too much wire bending involved and I wanted to investigate alternatives to see if anything was able to fit my requirements better. Let’s consider the bridge CNI.
To recap what we’re looking for in this CNI: we want to be able to run pods on the same subnet as my home LAN, this ultimately requires some kind of L2 layer bridge combined with a DHCP IPAM. Nothing pre-existing fully supports this situation. Thus I ended up modifying and extending existing CNIs.
Bridge CNI
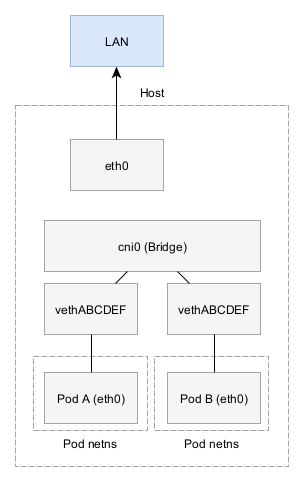
The bridge CNI’s IP stack
The Bridge stack is slightly different that the MACvlan stack. On the host side, we now have a point-to-point adapter (prefixed with veth*). These are added to the bridge and traffic from them can be routed between the adapters associated with the bridge.
Starting with the reference bridge CNI along with the following configuration:
| |
Unfortunately, the reference bridge CNI gives us the following errors in the Kubelet log:
| |
The DHCP daemon isn’t receiving any responses from the DHCP server. While the daemon is configured to use the host network, it assumes the Pod’s network namespace while sending the DHCP request packets. Taking a look at the pod’s network namespace, I see that the requests are being sent, but no responses are received:
| |
Looking at the host’s network adapter, we can see that they’re making it to the bridge, but not being sent outwards on eth0, thus the rest of the network won’t hear anything.
| |
Additionally, there are absolutely no routes in the Pod’s netns, thus nothing will ever work because it has no idea where to send packets. Luckily broadcast packets don’t need to be routed, so they somehow manage to get to host’s bridge adapter.
| |
This should be an easy fix since the bridge plugin contains two different configuration options: isGateway and isDefaultGateway. We should be able to set one of these to true and it should work. Unfortunately, it decides to use the gateway as returned by the IPAM plugin (see here). In the DHCP IPAM case, this is the IP of the network’s router (192.168.2.1) not the local host (192.168.2.125) which we want everything to forward through to get IPTables.
The fix for this is the same as in the MACvlan CNI. As part of the CNI, I need to define routes that forward all traffic to the host’s IP. I modified the bridge CNI code here. Ultimately, it gets the host’s primary IPv4 address (IPv6 to come later) and creates a default route to send all traffic to the host. Note that we again
| |
Great, now the Pod has the correct routes:
| |
DHCP still doesn’t work though. Looking back at the IP stack diagram, there’s a missing link from the bridge to eth0:
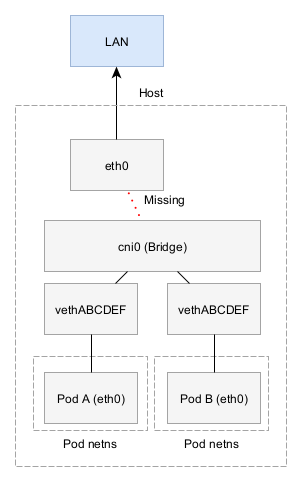
This is confirmed using the brctl command:
| |
That means we need to add the eth0 interface to the bridge. This is done here. The code (error handling removed) below shows how it works. First, we need to copy the IP address from eth0 to the bridge. This is because the bridge interface will effectively replace eth0 as the primary interface handling all traffic for even this host. Then we call LinkSetMaster to add eth0 into the bridge.
| |
Unfortunately this caused my SSH connection to disconnect after a minute and still prevent traffic. To fix this, we need to move the routes to the bridge interface because it needs to effectively replace eth0 as the primary interface.
In the code below, we get the routes defined on eth0 so we can add them to the bridge. This failed at first with Linux giving a syscall error.
This was tricky to figure out, but in Linux you can’t define a route that points to a destination, that Linux doesn’t also know how to find. For example, defining the route default via 192.168.2.125/32 means that you also need to define where to find 192.168.2.125/32. In most networks, you get a free route defined, 192.168.2.0/24 dev eth0, that tells Linux to find that IP on the eth0 interface, but in our case we’re explicitly defining all routes so that doesn’t work. We need to define 192.168.2.125/32 dev eth0, then define default via 192.168.2.125.
As a simple trick, I sort the routes based on their mask length so more specific routes appear first in the slice.
After sorting it, I remove it from eth0 and add it to the bridge.
| |
Now I have a route table that looks like this and my pods are able to work on RancherOS:
| |
Of course, what would this blog series be without a new problem to solve. When I tried running this on an Ubuntu machine, I encountered more issues with networking as DHCP requests were not making it out to the network.
As it turns out, there’s a difference in the default IPTables rule set between Ubuntu Server and RancherOS.
In RancherOS, the FORWARD chain has a default value of ACCEPT:
| |
Whereas, Ubuntu Server has a default value of DROP:
| |
This means we’re going to have manage IPTables rules that permit each pod to communicate with the network. Stay tuned for the next post where we extend the CNI to include IPTables rules.
