In the previous post (DHCP IPAM), we successfully got our containers running with macvlan + DHCP. I additionally installed MetalLB and everything seemingly worked, however when I tried to retroactively add this to my existing Kubernetes home lab cluster already running Calico, I was not able to access the Metallb service. All connections were timing out.
A quick Wireshark packet capture of the situation exposed this problem:
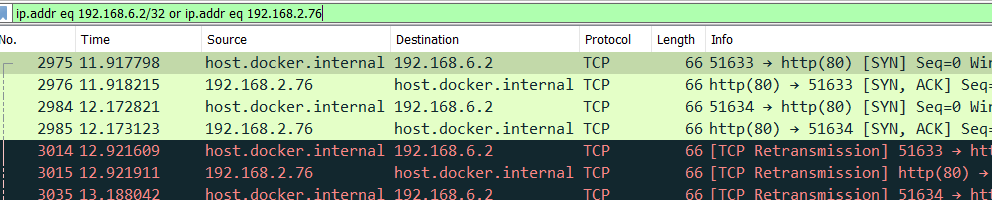
The SYN packet from my computer made it to the container (LB IP 1921.168.6.2), but the responding SYN/ACK packet that came back had a source address of 192.168.2.76 (the pod’s network interface.) This wouldn’t work because my computer ignored it because it didn’t belong to an active flow.
On the far side, Metallb is responsible for destination NATing (DNAT) by rewriting the destination IP from 192.168.6.2 to the pod’s IP 192.168.2.76, then the response packets are supposed to be source NATed (SNAT) so that the client computer only sees the LB IP address.
Checking out iptables -t nat -L -v, we see the difference in two different chains. One has KUBE-MARK-MASQ, the other doesn’t.
| |
At first, I thought Calico was doing something different between these two services, because when changed back to Calico, it worked correctly. But this was only partially correct. There were two main differences.
The first difference was that the service that worked had externalTrafficPolicy: Cluster, but the service that wasn’t working had externalTrafficPolicy: Local. In Cluster mode, the source IP address is rewritten to use the host’s IP address, whereas Local only DNATs the packet. (Here is useful blog post)
Usually the link doing NAT will remember how it mangled a packet, and when a reply packet passes through the other way, it will do the reverse mangling on that reply packet, so everything works.
IPTables automatically handles the packets flowing in the reverse direction, but are our packets being processed by the host’s IPTables?
My new containers were using the following routing table:
| |
In this route table, all packets (except for K8s cluster local IPs) would get forwarded to the destination switch port and bypass the host’s iptables rule set. In the previous post, this already caused problems with the K8s service routing.
The packets were following a path like this:
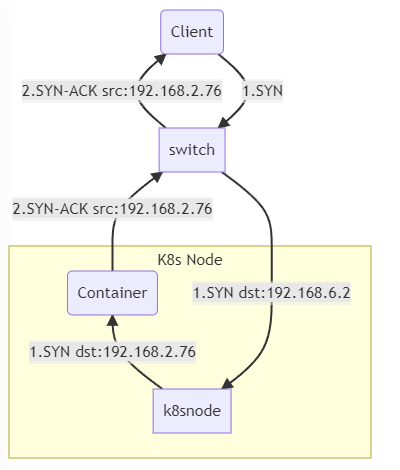
However, Calico used a different routing table where all traffic was routed through 169.254.1.1. Calico’s FAQ mentions this here.
| |
The packets were following a path where all packets were being forwarded through the host’s iptables rule set.
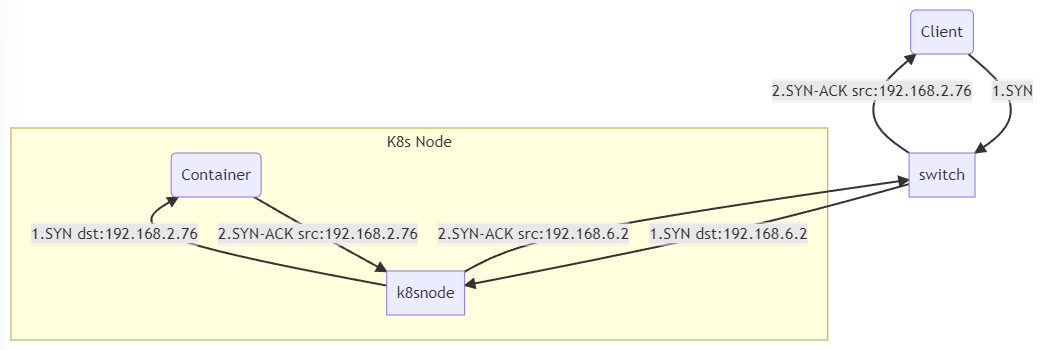
Thus, we need to change the route tables so that everything flows through the host.
This seems like it would be easy to do, but the following config:
| |
Results in the following route table:
| |
The second route allows traffic destined to the local subnet to continue bypassing the host’s IP stack. If you’re not on the local subnet, then it does work correctly.
I was not able to get the routing tables corrected using the route-override CNI plugin. Setting flushroutes: true wouldn’t delete this route because of this check:
| |
If you know how this mystery route is created, let me know in the comments.
Instead, I ended up forking the CNI references plugins and writing a custom plugin that setup my routes explicitly. Resulting in the following route table:
| |
Partial success.
Surprise Issues with MACvlan
Now, I’m able to load it using the LB, but I can’t ping the pod IP, but the pod can ping outwards. After much investigation, I tracked this down to an IPTables rule that was dropping INVALID connections.
| |
Why are these packets considered INVALID by conntrack when outbound pings from the pod itself are able to succeed? My guess is that inbound packets are again bypassing the host IP stack going directly to the pod network stack as macvlan is supposed to do.
TBD: Figure out how to fix this. My temporary solution is to override the DROP command and force IPTables to pass any traffic coming from the containers.
| |
These problems are suggesting that maybe MACvlan is the wrong technology to use here. I previously ruled out using bridge because it was lower performance and required the kernel to ’learn’ STP and MACs, of which we shouldn’t need.
Writing a custom CNI Plugin
Let’s review how I wrote a new CNI plugin:
The CNI plugins repository contains a sample CNI that we can use. For brevity, I’m going to exclude error handling
| |
The default route needs to point towards the host’s IP address, so we need to grab that. In the future, this should be configurable.
| |
Now, we switch to the context of the container’s network namespace and iterate over the interfaces and purge all routes. Nothing survives.
| |
Next, we tell Linux which interface the gateway IP lives.
| |
Finally, we add the default route telling Linux to forward everything to the host’s IP stack.
Then our CNI config (/etc/cni/net.d/0-bridge.conflist) looks like:
| |
To simplify everything, I’ve also changed the mac0 interface IP address to explicitly 169.254.1.1 to follow in Calico’s model. This is all handled by the custom CNI I wrote in the section below.
| |
If you’re not using RancherOS, the important part is:
| |
Custom CNI
This is deployable with the following K8s YAML:
| |
Stay tuned for more work on the cluster.
