The Problem
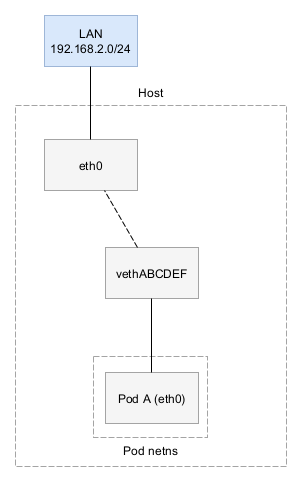
In my previous post series, I described how I installed my Kubernetes Home Lab using Calico and MetalLB. This worked great up until I started installing smart home software that expected to be able to do local network discovery. For example, Home Assistant and my Sonos control software both attempted to do subnet local discovery using mDNS or broadcast packets. This did not work because the pods were running on a 192.168.4.0/24 subnet, but all of my physical devices were on 192.168.2.0/24.
This prevented Home Assistant from discovering any devices and had to be fixed.
Calico isolates each pod into it’s own broadcast domain. Notice how the brd address is the same as the adapter IP address.
| |
When Home Assistant tries to scan for devices using the broadcast address, it will stay inside the Pod. Queries to 255.255.255.255 will hit the host stack, but will not be rebroadcast onto the LAN subnet. Multicast traffic, used by mDNS, also is not supported, but according to the FAQ it may be possible to support with a Multicast software router.
Options
Host Network
One option would be to run pods with hostNetwork: true so that every pod will runs on the end up with a 192.168.2.225 (in my case) address. This enabled Home Assistant to be able to discover devices on my LAN, but it had a number of disadvantages such as not being able to do rolling upgrades and software that tried to use the same ports would conflict with each other.
IPv6
But what about IPv6? Great question. Unfortunately, I’ve found most K8s software to be lacking in IPv6 support. It’s coming soon and when it does, some of our problems will be solved, but not all of them.
Reuse the same subnet
The current IP network plan looks like this:
- 192.168.2.0/24 - Home network subnet
- 192.168.2.225/32 - The RancherOS VM IP
- 192.168.4.0/24 - Kubernetes pod subnet
- 192.168.6.0/24 - MetalLB subnet
Instead of using 192.168.4.0/24, could we change it so that the Kubernetes pod is also 192.168.2.0/24?
Pretty much any CNI (like Calico) will manage it’s own IP reservations for pods since it assumes it has full control over the IP range. If we tried to change the Calico IP Block to be 192.168.2.0/24, it wouldn’t work. Thus we have several requirements:
- The DHCP server (an EdgeRouter) should not hand out IP address reservations that conflict with a K8s Pod IP addresses
- The K8s CNI plugin must be configured with the same subnet mask as the LAN. It can’t be configured as (e.x. 192.168.2.192/26)
- The K8s CNI plugin should not use IP addresses that are used by hardware devices
- The K8s CNI plugin needs at least one /26 block per node
- The K8s node must properly respond to ARP requests for all pod IP addresses.
Requirements #1 - #4 are related. They just require us to split the subnet up into parts such that both services don’t conflict.
My router provides the ability to define the start and end IP address in the DHCP block:
| |
However, I’m currently using IP addresses over the entire IP range which means there isn’t a clean place to carve out a /26 block without re-addressing multiple devices on my network. An alternative to this (assuming we can solve all conflict issues) would be to change the IP Addr Plan to be:
- 192.168.2.0**/23** - New super subnet (.2.0 - 3.255)
- 192.168.2.0-192.168.2.255 - Home devices
- 192.168.2.225/32 - The RancherOS VM IP
- 192.168.3.0-192.168.3.254 - Kubernetes pod range
- 192.168.3.255 - Broadcast address
- 192.168.2.0-192.168.2.255 - Home devices
- 192.168.6.0/24 - MetalLB subnet
With this change, we expand the size of the existing subnet to include 192.168.3.x. This avoids us having to readdress any existing physical devices, but it does mean that the pods need to move. This is a lot easier because nothing hard-codes those addresses in my network.
Assuming we can carve out one or more /26’s in our block, we still need to get Calico not use those IP addresses because we have to configure Calico to use the same subnet mask as the LAN or else K8s pods will use the wrong broadcast address.
I looked around the Calico documentation if it’s possible to exclude certain IP addresses from their IP block assignment logic and found one GitHub issue that talked about this. The maintainers suggest that there’s a calicoctl ipam reserve command, but nothing seemed to exist in the codebase or documentation. However, a recent commit (at the time of this post’s writing) suggests IP reservation support is being added in v3.22 and this doc in nightly supports that . This may be an option.
Interestingly, if we do move all DHCP addresses to <.192 and allow one /26 on the top end of the block at 192.168.2.192/26, we’d get the range 192.168.2.192 - 192.168.2.255 with the broadcast IP address also matching the broadcast for 192.168.2.0/24. I’m not sure if this would actually happen to work. However, it only allows a single worker node and still doesn’t solve our next requirement.
Requirement #5 is the tricky one.
First, a quick review how Calico currently works.
ARP (Address Resolution Protocol) is the mechanism that switches use to translate IPv4 addresses into the correct MAC address that the switch should forward the packet to. If it hasn’t learned what switch port a given IP address is, it uses ARP to figure out what switch port packets should be destined to.
In Calico BGP mode, we don’t use ARP because Calico would directly announce a set of pod IP addresses to the router (See below)
| |
All pods that are running on the 192.168.2.225 VM are going to be in the range 192.168.4.192/26.
We can also see that the switch doesn’t know the MAC address of any K8s pods, however it does know where to find the RancherOS VM running the pods:
| |
As soon as K8s assigns a pod to this node, Calico picks an unused IP address in this range. Calico stores IP addresses for assignment to pods in a K8s resource like below:
| |
Calico uses Layer 3 routing instead of Layer 2 routing because it’s more scalable than layer 2 routing. If I were to have hundreds of servers and thousands of K8s pods, layer 2 routing with switches trying to ARP request for every single pod would cause a significant amount of Ethernet protocol overhead.
This is specifically called out in the Calico documentation here.
[…] In a Calico network, the Ethernet interconnect fabric only sees the routers/compute servers, not the end point. In a standard cloud model, where there is tens of VMs per server (or hundreds of containers), this reduces the number of nodes that the Ethernet sees (and has to learn) by one to two orders of magnitude. […]
However, I don’t have hundreds of servers, I just have one server in my home lab and this is a trade-off that enables more seamless K8s routing configuration in a small network. I’m expecting my switch to be able to handle the traffic. If not, we’ll revisit this.
That being said, Calico won’t respond to ARP requests to the individual pod addresses. Thus, Calico will need to announce the node /26 to BGP even though it’ll overlap with a directly connected switch route. An example route table below:
| |
This is almost fine since routers will pick the most specific route to forward the packets to, however the Layer 2 switches will have no idea what to do with packets and they’ll desperately try to send ARP requests if another computer on the same network (not the router) tries to communicate with this pod.
What about Proxy ARP?
Proxy ARP is a mechanism in which one computer responds to ARP requests for an IP address for other machines and responds with its own MAC address. It’s almost like MAC address rewriting. Proxy ARP requires the host to have static routes for all the containers, which Calico takes care of for us:
| |
This may be an option, however many people complain about Proxy ARP breaking behavior unexpectedly, so we need to be careful. We only want Proxy ARP on the inbound side towards the node, but not to Proxy ARP from containers towards the network. Additionally, we’re going to be going outside the norm for Calico
Back to the proposal
In conclusion, we find that:
- Calico does not yet support reserving IP addresses but this is expected in v3.22. This is a hard requirement
- We either have to expand our subnet to avoid conflicts between DHCP reservations and Calico or move a lot of my existing home network devices around
- Our only solution for ARP responses seems to be to enable Proxy ARP on the node
This option sounds feasible, but has a number of caveats. Let’s review other options.
To be continued in a future post…
